
CNN and Program Loudness Tolerance
I recently analyzed a few of the internal Podcasts produced by CNN. One particular installment is yet another example of a major media outlet distributing audio that is in my view unsuitable for this particular platform.
Let’s discuss file attributes and measured specs. for one of CNN’s distributed Podcasts:
The distributed audio is mono, 64kbps, with music elements. I’ve stated how I feel about this. I’m not a proponent of 64 kbps MP3 audio PERIOD (mono or stereo). In general audio in this format sounds horrible. Feel free to disagree.
Secondly, the Integrated (Program) Loudness for this particular program is just about -23.0 LUFS with a Maximum True Peak of +0.40 dBTP. From my perspective the perceptual Loudness misses the mark. And, the audio is clipped.
Lastly, the produced audio is way too dynamic for spoken word. The perceptual inconsistency of the delivery by the participants is inadequate when considering how (for the most part) this program will be consumed (mobile devices, problematic ambient spaces, etc.).
I decided to sort of showcase this particular program because it is a good candidate for flexible Target considerations. What do I mean by “flexible Target considerations?” Let me explain …
Again, the distributed file is mono. The recommended Integrated Loudness Target for mono Podcasts is -19.0 LUFS. This is the perceptual equivalent of -16.0 LUFS stereo. If I were to apply a +4 db gain offset to Loudness Normalize this audio to -19.0 LUFS, there would be very little change to the original dynamic structure of the audio. However without some form of aggressive limiting, the maximum amplitude or Peak Ceiling would be driven into oblivion. In fact audible distortion may occur with or without limiting. This is obviously not recommended.
There are two options to consider: 1) apply Dynamic Range Compressionbefore Loudness Normalization, or 2) shoot for a lower Integrated Loudness target. For this particular example I chose to implement both options.
First, in my view optimizing the dynamics in this program for Podcast distribution is unavoidable. It’s just way too choppy and it lacks delivery consistency for spoken word. Also, by lowering the L.Normalized Target, the necessary added gain offset will be reduced resulting in less aggressive limiting. In addition, the reduced amount of added gain will curtail noise floor elevation and other variables such as exaggerated breaths.
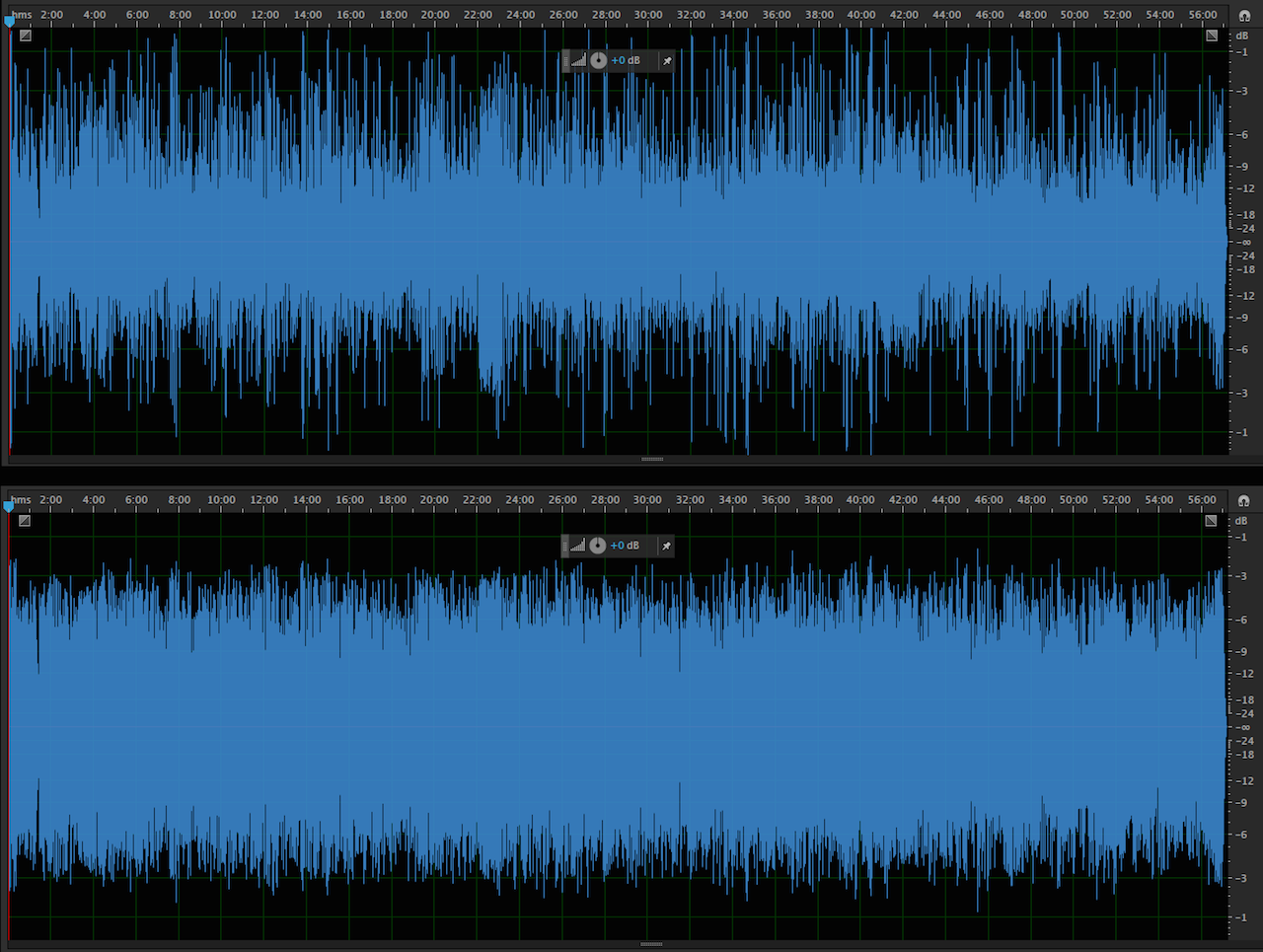
As noted the distributed Podcast (displayed in the attached upper waveform example) checks in at -23.0 LUFS and it is clipped. My optimized version (displayed in the lower waveform example) checks in at -20.2 LUFS with a Maximum True Peak of -1.23 dBTP. It is well within a reasonable level of Program Loudness tolerance for Podcast L.Normalization. In fact the perceptual difference between the processed -20.0 LUFS audio and a -19.0 LUFS version would be pretty much undetectable. In essence the audio has been optimized and it exhibits improved intelligibility. It is now well suited for Podcast distribution.
(If you are interested in the tools that I use, they are listed under Available Services).
It is no secret that I am a staunch proponent of the -16.0 LUFS/-19.0 LUFS recommendations for Podcasts. However, in certain situations – tolerance forslightly reduced Program Loudness Targets is acceptable.
For the record – my remaster is much easier to listen to. CNN can do better.
-paul.
Julian Ludwig é diretor do Pro Áudio Clube, produtora de áudio Jacarandá, Loc On Demand e Jacarandá Licensing. Trabalhou para empresas como: Guaraná Antartica, TV Gazeta, NET, Chivas Regal, FNAC, Prefeitura de São Paulo, Mukeca Filmes, Agência LEW’LARA TBWA, Agencia MPM, Agência Content House entre outras. Fez trilhas para programas de TV como: Internet-se (Rede TV), Você Bonita (TV Gazeta), Mix Mulher (TV Gazeta), Os Impedidos (TV Gazeta), Estação Pet (TV Gazeta), CQC (TV Band) Vinheta Oficial TV Gazeta, entre outras. Também atuou em vários longas e curtas metragens, incluindo mixagem em 5.1 e serviços de pós-produção.