Text-analyzing Brazilian music
FONTE: http://thiagomarzagao.com/2015/12/24/text-analyzing-brazilian-music/
People have text-analyzed American songs to exhaustion. We’ve learned, among other things, that pop music has become dumber and that Aesop Rock beatsShakespeare in vocabulary size. I thought it would be fun to make similar comparisons for Brazilian artists. Alas, as far as I could google no one has done that yet. So, I did it myself. Here’s my report.
the data
Our data source is Vagalume, from which I scraped the lyrics. (I give all the code in the end.) In total we have eight genres, 576 artists, and 77,962 lyrics (that’s after eliminating artists whose combined lyrics summed up to less than 10,000 words; more on this later). These are the genres:
- Rock.
- Rap.
- Samba. The music they play at the big Carnival parade in Rio.
- Pagode. Derived from samba but more popular, especially in the periphery of Rio de Janeiro.
- MPB. That slow, relaxing music you often hear in elevators.
- Sertanejo. Country music meets salsa.
- Axé. Think Macarena, but with racier choreographies. This is what they play at the Carnival parades in Bahia.
- Forró. Like salsa, but faster.
Here’s how the data are distributed:
(The genre assignment – which is Vagalume’s, not mine – is not exclusive: some artists belong to more than one genre. In these cases I arbitrarily picked one of the genres, to avoid double counting in the pie charts.)
how to measure vocabulary size?
At first glance vocabulary size is a simple metric: the number of (unique) words each artist uses. But some artists have only 2-3 songs while others have 400+ songs. Naturally the more lyrics you have (and the longer your lyrics) the more unique words you will tend to use (up to the point where you exhaust your vocabulary).
Can’t we divide the number of unique words by the total number of words, for each artist? No, we can’t. Say you know a total of 10,000 words and you have written 100 lyrics with 100 words each, without ever repeating a word. In this case your “unique words / total words” ratio is 1. But if you suddenly write another batch of 100 lyrics with 100 words each your ratio will fall to 0.5 – even though your vocabulary has remained the same. No good.
So, one measure (unique words) is overly kind to prolific artists while the other measure (unique words / total words) is overly kind to occasional artists. To get around that I: a) discard all artists whose combined lyrics sum up to less than 10,000 words (that’s how we got to 576 artists and 77,962 lyrics, down from 809 artists and 95,851 lyrics); b) for each non-discarded artist, randomly select 1,000 samples of 10,000 words each and compute the average number of unique words. In other words, I truncate my data and then use bootstrapped samples.
One final issue before we dive into the data. Naturally, the person singing the song is not necessarily the person who wrote the song. So when I talk about artist XYZ’s vocabulary that’s not really his or her personal vocabulary; that’s just short for “the vocabulary we find in the songs that artist XYZ sings”, which is too cumbersome to say. (And heck, no one is forcing people to go on stage and sing dumb songs. If they do it then they should bear the reputational cost.)
Enough talk, let’s see the data.
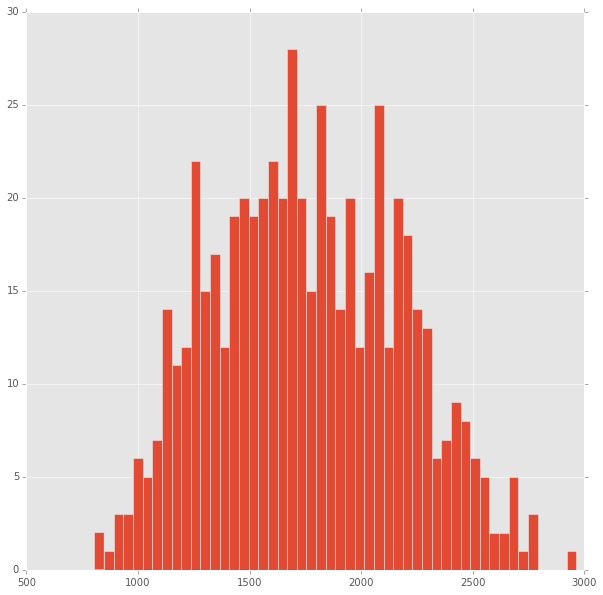
mandatory descriptive statistics
The mean vocabulary is 1,758 words and the 95% confidence interval is [1,120, 2,458]. N = 576. Here’s the distribution:

the 30 largest vocabularies
Ok, time to see the winners (mouse over each bar to see the corresponding number):
What do you know! The largest vocabulary of Brazilian music is that of a rap band: 2,961 words. That’s almost twice the mean (1,758) and almost four times the lowest vocabulary (804). Not bad. Street music beats highfalutin MPB: Chico Buarque would need to learn some 200 new words to reach Facção Central.
Rap didn’t just take the first prize: rap bands occupy 16 of the top 30 positions. And that’s despite rap representing only 7% of our lyrics. Rap folks, take a bow.
Here, check Diário de um Detento, by Racionais Mc’s. It’s one of their most famous songs. And it’s pretty representative of Brazilian rap music, as it talks about life in the periphery of the big cities – violence, drugs, poverty, etc.
Another big surprise (to me at least) was sertanejo, which occupies 4 of the top 30 positions. When I think about sertanejo what comes to mind are cheesy duos like Zezé di Camargo & Luciano or Jorge & Mateus. The sertanejo singers we see above were completely unfamiliar to me.
I googled around and turns out these are all old-timers, mostly retired. So, it seems that what has now degenerated into tche tcherere tche tche was once a vocabulary-rich genre. (Unfortunately Vagalume doesn’t have lyrics’ release dates, so we can’t do a proper time series analysis.)
Same with Luiz Gonzaga: when I think forró I imagine tacky bands like Banda Calypso or Aviões do Forró. But Luiz Gonzaga is an old-timer. So, yet another vocabulary-rich genre has degenerated – this time into “suck it ‘cause it tastes like grapes”.
Rap, vintage sertanejo, and Luiz Gonzaga aside, what we see above are MPB’s biggest stars. These are world-renowned artists with long and established careers. You won’t find their songs among Spotify’s top 50, but they have their public. (Fittingly, Chico Buarque is a distant relative of Aurélio Buarque de Hollanda, the lexicographer who edited the most popular dictionary of Brazilian Portuguese.) I find most MPB mind-numbingly boring but here’s a playlist of Chico Buarque’s songs, so you can check for yourself.
One absence is noteworthy: rock. I was sure folks like Raimundos and Skank would come out on top. Alas, I was wrong. Raimundos’ vocabulary is 2,239 and Skank’s, 2,246 – they rank #81st and #79th respectively. Not exactly bad, but far from top 30. (I keep hearing that Brazilian rock is dead; maybe that’s true after all.) Anyway,here’s a Raimundos’ song, in case you’ve never had a taste of Brazilian rock before.
Here are the most frequent words of the top 30 artists:

No clear dominant theme here. Life (vida), other (outro), brother (irmão), water (água), path (caminho), moment (momento), soul (alma), hour (hora), dream (sonho), star (estrela), son (filho), hand (mão), night (noite), word (palavra), time (tempo), year (ano), stone (pedra), eye (olho), father (pai).
the 30 smallest vocabularies
Now on to the losers:
Sertanejo is by far the most frequent genre here: it takes up 12 of the bottom 30 positions. I can’t say I’m shocked. (I googled around and these are all contemporary sertanejo artists; no old-timers here.)
I can hear sertanejo fans complaining: “wait, maybe it’s just that sertanejo is overrepresented in the data” (though, given what we just saw, one wonders whether many sertanejo fans would know the word “overrepresented”; or “data”). Indeed, sertanejo accounts for 28% of our lyrics – by far the largest piece of the pie. But then how come not a single contemporary sertanejo artist appears in the top 30? Sorry, sertanejo fans: it’s time to acknowledge the misery of your musical taste and look for something better (the top 30 above might be a good place to start).
Rock is the second most represented category here. A bit of a surprise to me. I mean, fine, there isn’t a single rock artist in the top 30; but dammit, must rock also account for a fifth of the bottom 30? If Brazilian rock isn’t dead yet then maybe it’s time we euthanize it.
The rest is forró and pagode, about which no one could seriously have had high expectations (if you did then your musical taste is beyond hope; just give up on music and download some podcasts instead).
I expected axé to be in the bottom 30. Maybe Carnival in Bahia is not the nightmarish experience I picture after all.
The amplitude of the spectrum is large. The average of the top 30 vocabularies is 2.6 times larger than the average of the bottom 30 vocabularies. Maybe this will help you grasp the abyss: the combined vocabulary of Victor & Vinicius, Abril, Lipstick, Agnela, Lucas & Felipe, Forró Lagosta Bronzeada, Leva Nóiz, Hevo84, Forró Boys, Drive, Cacio & Marcos, Marcos & Claudio, Banda Djavú, Renan & Ray, Raffael Machado, TNT, Sambô, and Roberta Campos (after accounting for the words that they all have in common) is still smaller than the vocabulary of Racionais Mc’s alone.
In short, it’s official: Brazilian popular music is garbage. And now we have data to back up that claim.
If I’m allowed a short digression, the problem is not just the poverty of the vocabulary but the poverty of the underlying sentiments and ideas as well. Let me give you a taste. What you see below is Michel Teló’s “Oh, if I catch you” (I translated it for your benefit):
Wow. Wow.
This way you’ll kill me.
Oh, if I catch you.
Oh, if I catch you.
Delicious. Delicious.
This way you’ll kill me.
Oh, if I catch you.
Oh, if I catch you.
Saturday in the club.
People started dancing.
Then the prettiest girl passed by.
I got bold and went talk to her.
(repeat)
So: guy is in the club, sees pretty girl, goes talk to her. Next to Michel Teló Nicki Minaj is Chaucer.
No, I didn’t pick some little-known, abnormally bad outlier song just to make things appear worse than they are: “Oh, if I catch you” reached #1 in 23 European and Latin American countries. There is even a The Baseballs version, if you can believe that. Michel Teló is export-grade garbage.
Here are the most frequent words of the bottom 30 artists:

Romantic words are a lot more frequent here than in the top 30: kiss (beijo), love (amor), hurt/hurts (dói), together (junto), “missing someone/something” (saudade; kinda hard to translate this one), heart (coração), and so on. We also see that “thing” (coisa) is possibly the most frequent word here, which tells us that these artists are not even trying (they have no concept of le mot juste).
the middle of the scale
The extremes tell a pretty coherent story: rap, MPB, and vintage sertanejo on one end, forró, pagode, and contemporary sertanejo on the other. But things get fuzzier as we move away from the extremes. Here are some surprises:
- Chiclete com Banana, an axé band whose best-known chorus is “aê aê aê aê aê”, beats MPB god, Grammy-winner, Girl from Ipanema co-author Tom Jobim.
- Daniel, a corny sertanejo singer, beats Maria Rita and Toquinho, two revered favorites of MPB fans.
- Legião Urbana, a mediocre rock band that is insufferably popular in Brasília (where I live), only appears in the #188th position – behind forró band Mastruz com Leite.
- And my favorite finding: Molejo, Aviões do Forró, and Wesley Safadão, respectively the trashiest pagode band, forró band, and sertanejo singer of all times, all beat Grammy-winner, celebrated MPB singer and composer Maria Gadú.
Here’s the whole data if you’re interested.
to do
There is a lot more we could do with these data. For instance, we could do some sentiment analysis. There is no word->sentiment dictionary in Portuguese, but we could use automatic translation and then use SentiWordNet. I suspect that axé and sertanejo will be at opposite ends of the happy-sad spectrum.
We could also use co-sine similarity to check how “repetitive” each genre is. To me all axé songs sound the same, so I suspect there is little textual variation in them. We could, for each genre, take each possible pair of songs and compute the average co-sine similarity of all pairs
Just because you have a large vocabulary doesn’t mean you pick the right words. A plausible observable implication of careful word choice is the use of rarer, lesser-known words. So it might be worthwhile to compute the average inverse document frequency (IDF) of each artist and compare them.
I read somewhere that sertanejo, forró, and pagode are beginning to merge into one single genre (I shudder at the thought of a song that is simultaneously sertanejo, forró, and pagode). I wonder if that may already show in our data, so it migh be interesting to clusterize the lyrics (say, using k-means) and check whether the resulting clusters correspond to genre labels.
Finally, we could use recurrent neural networks (RNN) to automate some artists (like people have done with Obama), just for the fun of it. As with any RNN the more training texts the better, so Chico Buarque, with his 416 lyrics, would be a great candidate for automation. I bet that most of his fans wouldn’t be able to tell human Chico Buarque from bot Chico Buarque.
code
Here’s the Python code I wrote to scrape Vagalume:
'''
scrape lyrics from vagalume.com.br
(author: thiagomarzagao.com)
'''
import json
import time
import pickle
import requests
from bs4 import BeautifulSoup
# get each genre's URL
basepath = 'http://www.vagalume.com.br'
r = requests.get(basepath + '/browse/style/')
soup = BeautifulSoup(r.text)
genres = [u'Rock']
u'Ax\u00E9',
u'Forr\u00F3',
u'Pagode',
u'Samba',
u'Sertanejo',
u'MPB',
u'Rap']
genre_urls = {}
for genre in genres:
genre_urls[genre] = soup.find('a', class_ = 'eA', text = genre).get('href')
# get each artist's URL, per genre
artist_urls = {e: [] for e in genres}
for genre in genres:
r = requests.get(basepath + genre_urls[genre])
soup = BeautifulSoup(r.text)
counter = 0
for artist in soup.find_all('a', class_ = 'top'):
counter += 1
print 'artist {} \r'.format(counter)
artist_urls[genre].append(basepath + artist.get('href'))
time.sleep(2) # don't reduce the 2-second wait (here or below) or you get errors
# get each lyrics, per genre
api = 'http://api.vagalume.com.br/search.php?musid='
genre_lyrics = {e: {} for e in genres}
for genre in artist_urls:
print len(artist_urls[genre])
counter = 0
artist1 = None
for url in artist_urls[genre]:
success = False
while not success: # foor loop in case your connection flickers
try:
r = requests.get(url)
success = True
except:
time.sleep(2)
soup = BeautifulSoup(r.text)
hrefs = soup.find_all('a')
for href in hrefs:
if href.has_attr('data-song'):
song_id = href['data-song']
print song_id
time.sleep(2)
success = False
while not success:
try:
song_metadata = requests.get(api + song_id).json()
success = True
except:
time.sleep(2)
if 'mus' in song_metadata:
if 'lang' in song_metadata['mus'][0]: # discard if no language info
language = song_metadata['mus'][0]['lang']
if language == 1: # discard if language != Portuguese
if 'text' in song_metadata['mus'][0]: # discard if no lyrics
artist2 = song_metadata['art']['name']
if artist2 != artist1:
if counter > 0:
print artist1.encode('utf-8') # change as needed
genre_lyrics[genre][artist1] = artist_lyrics
artist1 = artist2
artist_lyrics = []
lyrics = song_metadata['mus'][0]['text']
artist_lyrics.append(lyrics)
counter += 1
print 'lyrics {} \r'.format(counter)
# serialize
with open(genre + '.json', mode = 'wb') as fbuffer:
json.dump(genre_lyrics[genre], fbuffer)So, I loop through genres, artists, and songs. I get each song’s id and use Vagalume’s nice API to check whether the lyrics is available and whether it’s in Portuguese. For each genre I create a dict where each artist is a key and then I save the dict as a JSON file.
You’ll need the requests and BeautifulSoup packages to run this code.
Vagalume says that in the future you will need credentials to use their API (that’s how it works with Twitter, for instance). So, if you’re in the future you may have to change the code.
Here’s the code I wrote to measure the vocabularies:
'''
count vocabularies of lyrics scraped off vagalume.com.br
(author: thiagomarzagao.com)
'''
import os
import json
import nltk
import random
import pandas as pd
# organize lyrics by artist
basepath = '/path/to/JSON/files/'
rawdata = {}
for fname in os.listdir(basepath):
if '.json' in fname:
with open(basepath + fname, mode = 'rb') as fbuffer:
genre = json.load(fbuffer)
for artist in genre:
rawdata[artist] = genre[artist]
# compute statistics per artist
data = {}
for artist in rawdata:
print artist.encode('utf-8')
total_lyrics = 0
words = []
for lyrics in rawdata[artist]:
print(str(total_lyrics) + ' \r'),
lowercased = lyrics.lower()
tokens = nltk.word_tokenize(lowercased)
if len(tokens) < 2:
continue
total_lyrics += 1
for word in tokens:
words.append(word)
total_words = float(len(words))
unique_words = float(len(set(words)))
# discard if artist has less than 10,000 words
if len(words) >= 10000:
# bootstrap
uniques = []
for i in range(1000):
sample = random.sample(words, 10000)
uniques.append(len(set(sample)))
vocabulary = float(sum(uniques)) / len(uniques)
# store data
data[artist] = {'total_lyrics': total_lyrics,
'total_words': total_words,
'unique_words': unique_words,
'vocabulary': vocabulary}
df = pd.DataFrame(data).T.sort(['vocabulary'], ascending = False)You’ll need NLTK and pandas to run this code.
To produce the word clouds I used Andreas Mueller’s nifty word_cloud package.
Well, it’s a wrap. Say no to dumb music, kids!
Julian Ludwig é diretor do Pro Áudio Clube, produtora de áudio Jacarandá, Loc On Demand e Jacarandá Licensing. Trabalhou para empresas como: Guaraná Antartica, TV Gazeta, NET, Chivas Regal, FNAC, Prefeitura de São Paulo, Mukeca Filmes, Agência LEW’LARA TBWA, Agencia MPM, Agência Content House entre outras. Fez trilhas para programas de TV como: Internet-se (Rede TV), Você Bonita (TV Gazeta), Mix Mulher (TV Gazeta), Os Impedidos (TV Gazeta), Estação Pet (TV Gazeta), CQC (TV Band) Vinheta Oficial TV Gazeta, entre outras. Também atuou em vários longas e curtas metragens, incluindo mixagem em 5.1 e serviços de pós-produção.